
When you need to fetch multiple items from DynamoDB, it’s not always the right and efficient choice to do it using some combination of for loop and ‘get the item by id’.
This is where so-called batch operations make perfect sense as they reduce network overhead — for example, instead of several HTTP requests, batch operations return the data you asked for in a single network call.
This short tutorial demonstrates the implementation of fetching data from DynamoDB in batches using Appsync, AWS Amplify, and custom GraphQL resolvers (in templating language called Velocity). I will also show how to implement multi-table batches.
Are you looking for custom AppSync JS Resolvers ? Then check my other blog post: http://stefan-majiros.com/blog/geo-search-with-aws-amplify-cdk-and-appsync-custom-js-resolvers
As I am React Native / mobile developer/freelancer (Stefan Majiros) who has made living by selling custom-made mobile apps to my clients, I am also using React Native for this AWS Amplify tutorial. However, this approach would also work for web projects (ReactJS).
Let's Start With Creating React Native App with AWS Amplify
- Create new app with Typescript
npx react-native init AwesomeTSProject \
--template react-native-template-typescript2. Install Amplify CLI
npm install aws-amplify \
aws-amplify-react-native \
@react-native-community/netinfo \
@react-native-async-storage/async-storage \
@react-native-picker/picker3. Run Amplify Configure
amplify configureYou will be asked to set up an AWS account and to create a new IAM user in AWS Console for this project. After completion, this process will create an AWS profile into your local machine (if you are also using Mac, the AWS credentials for Amplify are stored at the path ˜/.aws/amplify/credentials).
4. Create new Amplify project
amplify initThen just wait few minutes until CLI creates new project.
BatchGetItem Limits
BatchGetItem operation has some limits (both in regard to response size, and items count):
A single operation can retrieve up to 16 MB of data, which can contain as many as 100 items.
If you request more than 100 items, BatchGetItem returns a ValidationException. For example, if you ask to retrieve 100 items, but each individual item is 300 KB in size, the system returns 52 items only (so as not to exceed the 16 MB limit). It also returns an appropriate Unprocessed Keys value so you can get the next page of results. The average size of the table item can be found in AWS Console, in the DynamoDB section. BatchGetItem documentation for more.
Implementing BatchGetItem GraphQL resolver for Appsync in AWS Amplify
The best way to understand resolvers in GraphQL is to imagine it as a code that transforms requests and responses when calling some service — in or outside AWS (such as DynamoDB, AWS RDS / Aurora, AWS Lambda function, or e.g. third-party HTTP service deployed at DigitalOcean).
Such resolver, which consists of single request-response pair of mappers / Velocity templates, is called unit resolver and is used by default in AWS Amplify. Just to tell the whole truth, there is also a pipeline resolver, that executes several unit resolvers sequentially and is able to share data between unit invocations.
For purposes of this tutorial, I used this simple GraphQL schema:
type Todo @model {
id: ID!
name: String!
description: String
priority: String
}
We would like to implement batchFetchTodo resolver (as a unit resolver, meaning it will consist of just two Apache Velocity templates).
The batchFetchTodo resolver takes a list of strings as the input (Todo’s ids) and returns them back as a list of fully-resolved Todos as the output.
Hint: When developing custom resolvers for Appsync, I recommend you to do it by running ‘amplify mock’ in the separate terminal window so you would see if there are any errors.
Adding Resolvers Content
Caution — Naming matters! Somewhere you will have to use table name, somewhere else you should use table name with Appsync API ID + env suffix
As we are creating unit resolver, we need to create two Velocity template files:
- the first resolver (Velocity template file) for request should be at the path of "amplify/backend/api/'apiName' /resolvers/Query.batchFetchTodo.res" and it should contain:
#if ($ctx.error)
$util.appendError($util.toJson($ctx))
#end
#set($ids = [])
#foreach($id in ${ctx.args.ids})
#set($map = {})
$util.qr($map.put("id", $util.dynamodb.toString($id)))
$util.qr($ids.add($map))
#end
{
"version" : "2018-05-29",
"operation" : "BatchGetItem",
"tables" : {
"Todo-k5kf3yxdyzbqvlnh22m7xsolzm-dev": { ## 👈 this is table name with AppsyncApiId and env suffix
"keys": $util.toJson($ids),
"consistentRead": true
}
}
}Note: If you are using BatchGetItem that is targeting DynamoDB, you should remember to provide list of ids without duplicates, otherwise DynamoDB will throw an error. I am handling this in client, where I am creating Set in Javascript, as I found it easier to do there than in Velocity templates.
- second resolver (Velocity template) for response should be at the path of "amplify/backend/api/'apiName' /resolvers/Query.batchFetchTodo.res" with the content of
#if ($ctx.error)
## $util.error($ctx.error.message, $ctx.error.type)
$util.appendError($util.toJson($ctx))
#end
## 👇 this is table name with AppsyncApiId and env suffix
$util.toJson($ctx.result.data.Todo-k5kf3yxdyzbqvlnh22m7xsolzm-dev)Understanding content of resolver files
As previously mentioned, GraphQl resolvers are written in templating language called Velocity (from Apache).
AppSync resolvers come with a few utilities that are a superset of Velocity language. By using these extensions developed by AppSync, it is easier to work with:
- Dates
- DynamoDB (input transformation, or filters implementation)
- ElasticSearch/OpenSearch DSL (if you want to target OpenSearch instances)
See more docs here, if you are interested.
Error handling
To complete explanation above, this part in the templates above
#if ($ctx.error)
## option A: $util.error($ctx.error.message, $ctx.error.type)
## option B below:
$util.appendError($util.toJson($ctx))
#enddetermines if you want to return partial responses to the client or not:
- option A in the code sample above means: if there was an error, return null for data and forward the errors to the client separately
- option B means, if there was an error, return some data and forward the errors to the client separately (return partial response)
Choose which one suits you best. See more documentation here.
Adding New Query In Schema.graphql
After creating resolver files, we also need to add batchFetchTodo into schema.graphql (into special 'Query' type) like this:
type Todo @model {
id: ID!
name: String!
description: String
priority: String
}
type Query {
batchFetchTodo(ids: [ID]): [Todo]
}Required Changes For CloudFormation Templates
We also need to modify amplify/backend/api/batchgetexample/stacks/customResources.json where we need to add the following under "Resources" (caution: naming matters):
"QueryBatchFetchUserResolver": {
"Type": "AWS::AppSync::Resolver",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"DataSourceName": "TodoTable", 👈 table name without AppsyncID and env
"TypeName": "Query", 👈
"FieldName": "batchFetchTodo", 👈 should be same as in schema.graphql
"RequestMappingTemplateS3Location": {
"Fn::Sub": [👇 make sure you have correct filename here
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.batchFetchTodo.req.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
},
"ResponseMappingTemplateS3Location": {
"Fn::Sub": [ 👇 make sure you have correct filename also here
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.batchFetchTodo.res.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
}
}
}If you run 'amplify mock' and get this error : Failed to start API Mock endpoint Error: Missing request mapping template make sure the resolver files are not empty (they contain valid Velocity code) and check the naming again (e.g. not using plurals, etc).
Usage & Testing BatchGetItem resolver with AWS Amplify locally
Here is how query for getting Todos using batch query would look like:
query MyQuery {
batchFetchTodo(ids: ["someIdHere", "secondId"]) {
id
priority
name
updatedAt
description
createdAt
}
}
If you do not want to wait for the deployment to the cloud (with running traditional amplify push command), you can run
amplify mockthat will launch both DynamoDB local and local AppSync console at http://192.168.0.17:20002 on your machine.
Here is an output from the local Appsync mock console when using the query above:
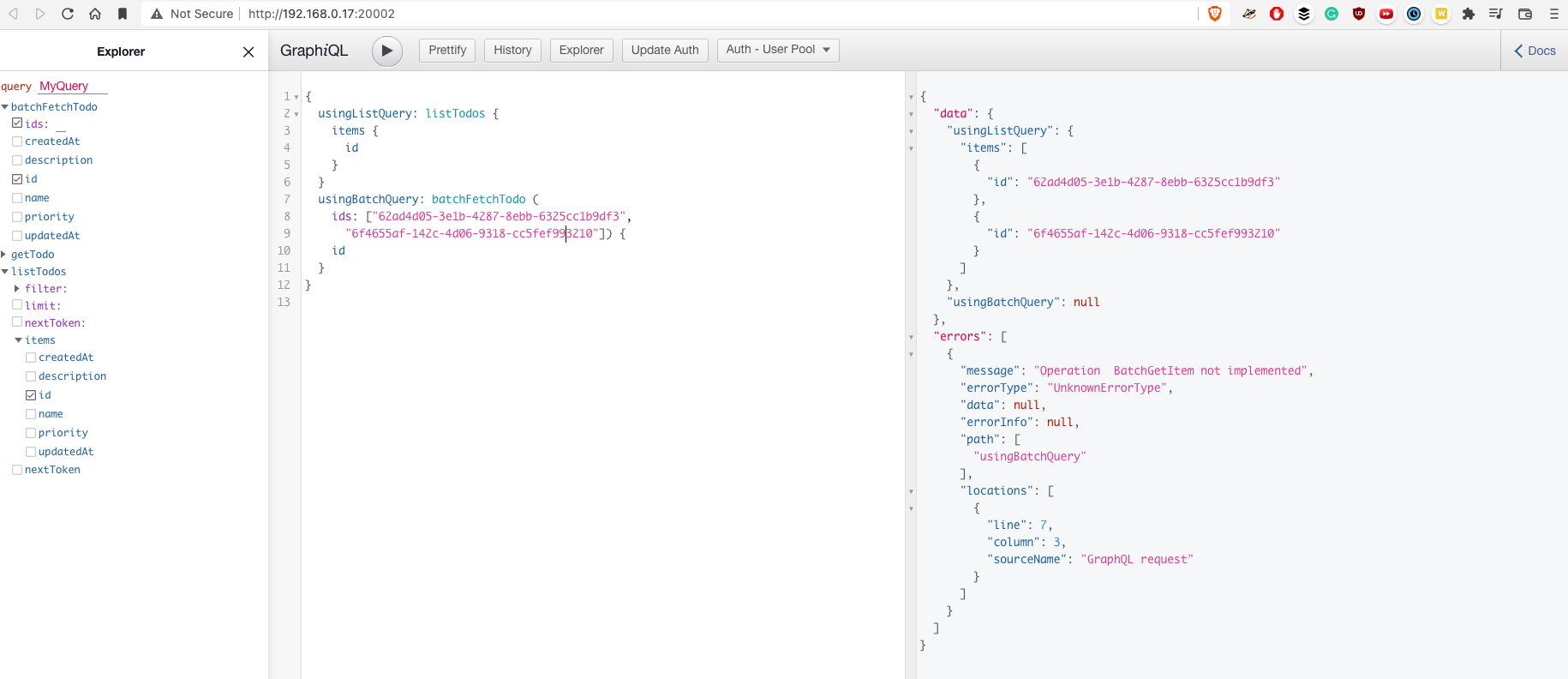
As you can see, there is the error for batch query: Operation BatchGetItem not implemented. Here is pull request from Oct, 2020 (note: it's still not merged in 23 Jan, 2022). I was using "aws-amplify": "^4.3.12" and "aws-amplify-react-native": "^6.0.2". If you know how to use patch-package, I would say you would be able to install modified version of Amplify CLI library.
If you decide you do not want to test batchGetItem locally, you can deploy it right now using 'amplify push' command, and it will work (at least, it worked in my case).
Another Note: When you are using an incorrect table name in resolver files ("TodoTable" in my case instead of something in format of "Todo-AppsyncApiID-env") you would get following error:
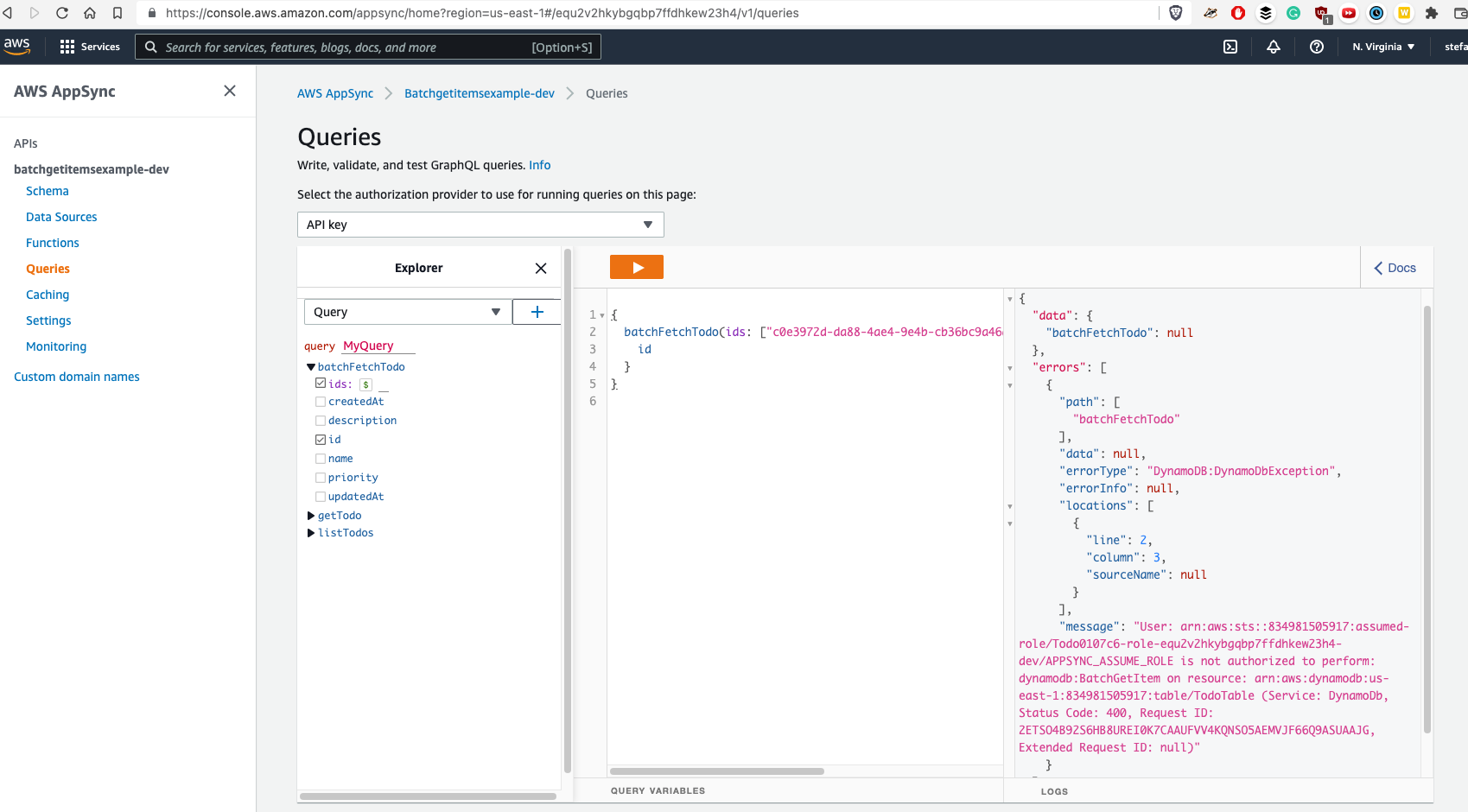
To find proper table name, you would need to open DynamoDB:
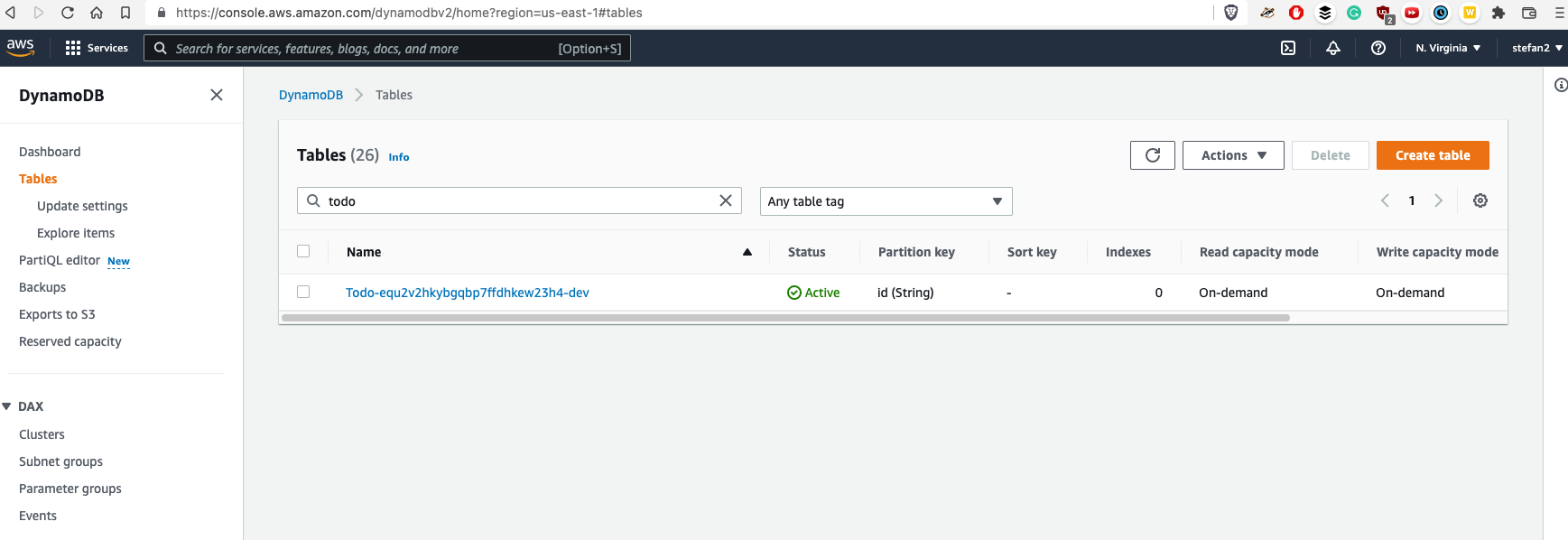
Then you will need to use found table name in both resolver files for request and response ('Todo-equ2v2...-dev' in the pic above) like this:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
$util.appendError($util.toJson($ctx))
#end
#set($ids = [])
#foreach($id in ${ctx.args.ids})
#set($map = {})
$util.qr($map.put("id", $util.dynamodb.toString($id)))
$util.qr($ids.add($map))
#end
{
"version" : "2018-05-29",
"operation" : "BatchGetItem",
"tables" : {
"Todo-equ2v2hkybgqbp7ffdhkew23h4-dev": { ## 👈 here
"keys": $util.toJson($ids),
"consistentRead": true
}
}
}#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
$util.appendError($util.toJson($ctx))
#end
## 👇 and here
$util.toJson($ctx.result.data.Todo-equ2v2hkybgqbp7ffdhkew23h4-dev)As you can see, there is one downside of this solution - table name for batch resolvers is hardcoded in VTL templates. This is tricky if you plan to use AWS Amplify with multiple environments (dev, staging, prod) as most of the real-world projects. Here is a bug to solve it (do not forget to check if it was resolved when reading this blog post).
There are a few possible solutions:
- keep table name hardcoded like it is, but you will need to include either manual or automatic step (probably with sed bash script utility) for your release pipeline (meaning if you use multiple AWS Amplify environments where table names are different)
- Another solution, is to use pipeline resolver (you still remember that there are two kind of resolvers, right ?). Pipeline resolver is a way how we can execute some other resolvers before or after our resolver - in sequence. See https://docs.aws.amazon.com/appsync/latest/devguide/resolver-mapping-template-reference-overview.html
There is this pull-request, but it seems like it was never merged.
🤯 Implementing Pipeline Resolver in AWS Amplify
The implementation process was a little tricky. Here is how you can image Pipeline resolvers (image is taken from AWS docs):
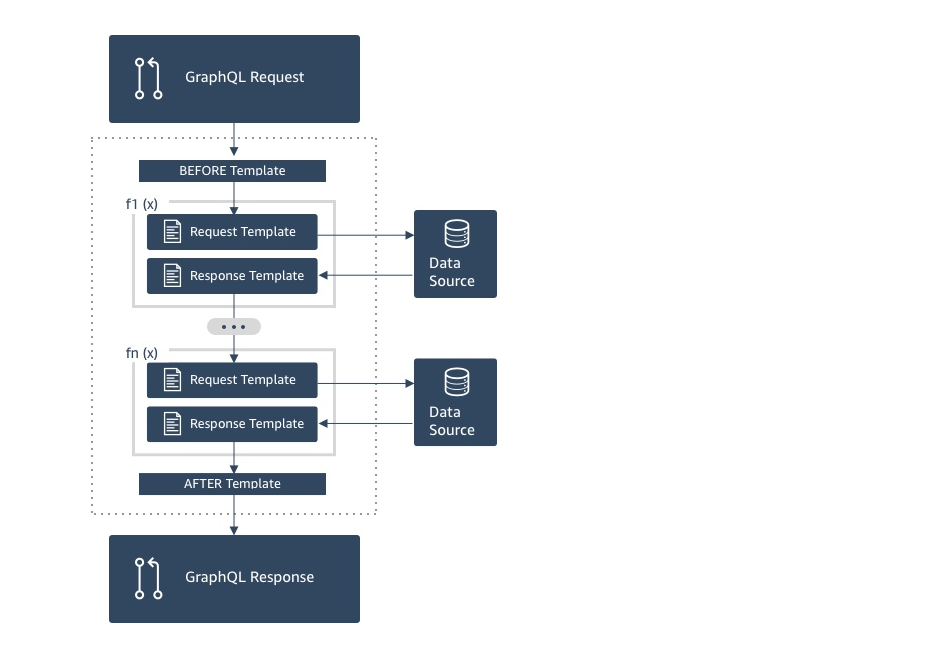
In our case, f1(x) will be function / first unit, that will fetch AppsyncApiId and current env and will save it in the context that could be shared with f2(x). F2(x) in our case will be the resolver / second unit, that is targeting DynamoDB table (or any other data source that Appsync can support).
To simplify naming, I will rename f1(x) to addEnvVariablesToStash. (note: 'stash' is part of the context that could be shared across functions).
If you asked yourself, and what will f1(x) will be targeting ? My answer is something like 'itself' - you would need to use special 'NONE' keyword to specify that.
Here is how addEnvVariablesToStash could look like:
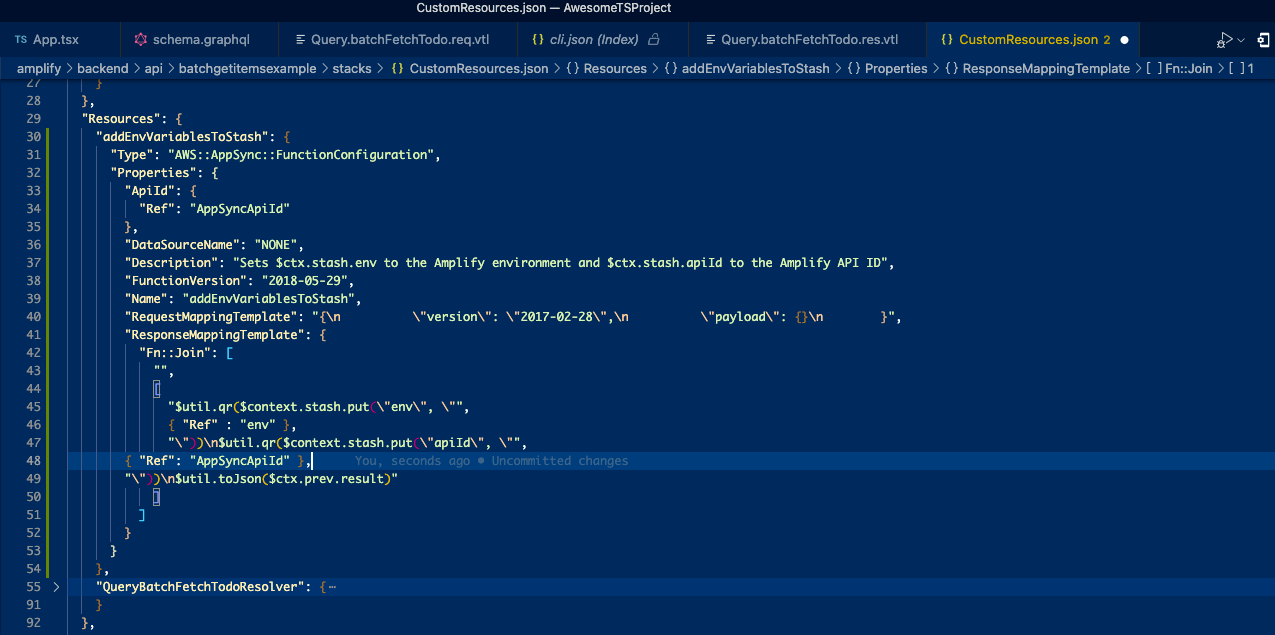
But for some reason, I experienced this error (here is a bug):
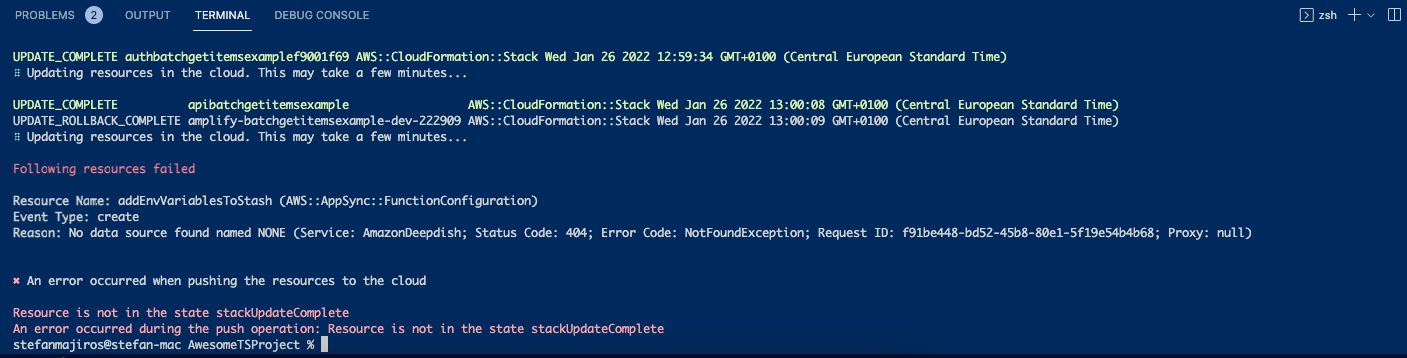
To be honest, I experienced few more errors and I needed to delete complete GraphQL API and add it again. After finishing the process, I experienced this error:
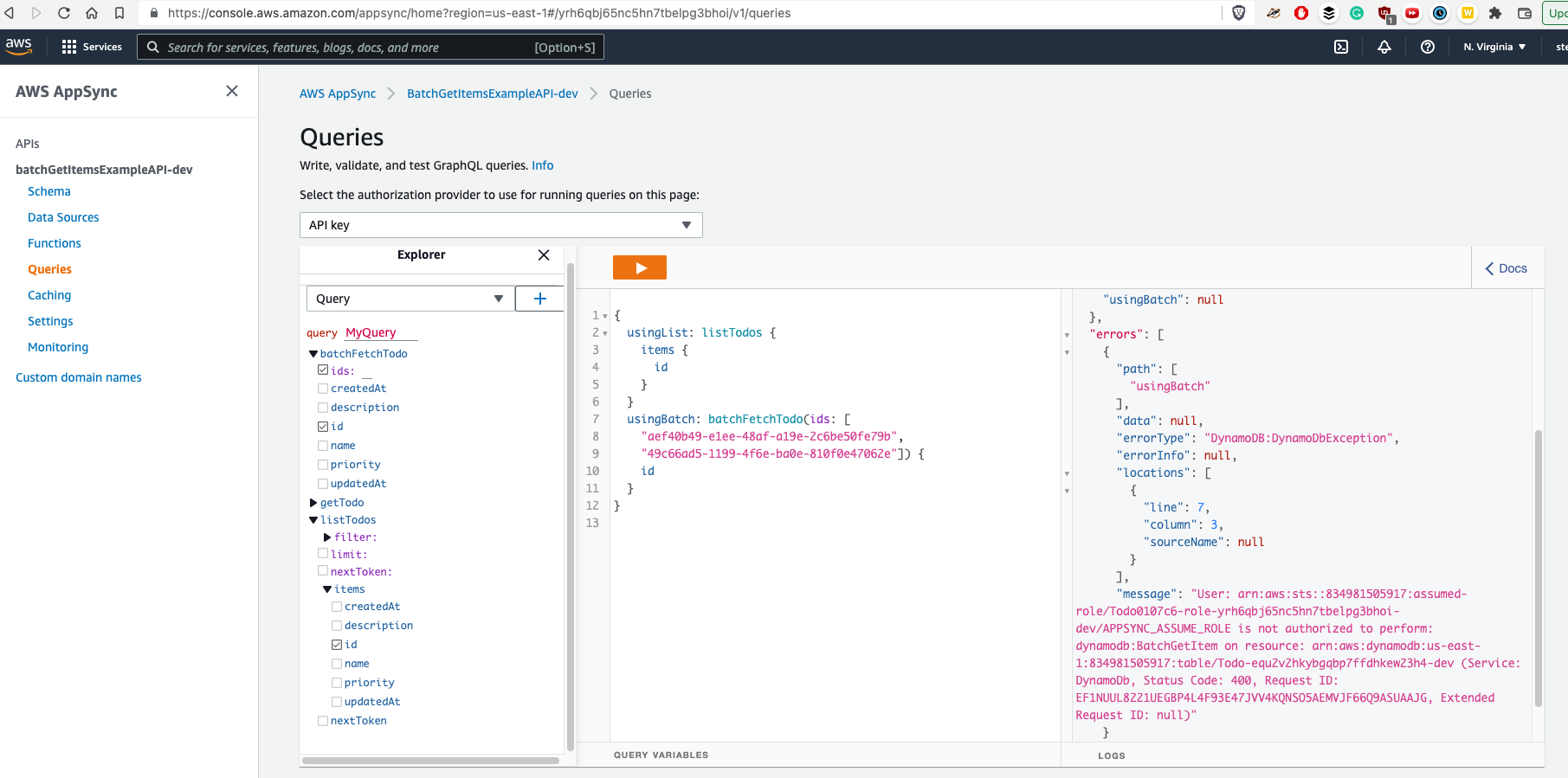
I was able to overcome it when I put following content into Resources key in CustomResources.json:
"Resources": {
"EmptyResource": {
"Type": "Custom::EmptyResource",
"Condition": "AlwaysFalse"
},
"NONEE": {
"Type": "AWS::AppSync::DataSource",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"Name": "NONEE",
"Type": "NONE"
}
},
"AddEnvVariablesToStash": {
"Type": "AWS::AppSync::FunctionConfiguration",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"DataSourceName": "NONEE",
"Description": "Sets $ctx.stash.env to the Amplify environment and $ctx.stash.apiId to the Amplify API ID",
"FunctionVersion": "2018-05-29",
"Name": "AddEnvVariablesToStash",
"RequestMappingTemplate": "{\n \"version\": \"2017-02-28\",\n \"payload\": {}\n }",
"ResponseMappingTemplate": {
"Fn::Join": [
"",
[
"$util.qr($ctx.stash.put(\"env\", \"",
{
"Ref": "env"
},
"\"))\n$util.qr($ctx.stash.put(\"apiId\", \"",
{
"Ref": "AppSyncApiId"
},
"\"))\n$util.toJson($ctx.prev.result)"
]
]
}
},
"DependsOn": [
"NONEE"
]
},
"FunctionQueryBatchFetchTodo": {
"Type": "AWS::AppSync::FunctionConfiguration",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"DataSourceName": "TodoTable",
"FunctionVersion": "2018-05-29",
"Name": "FunctionQueryBatchFetchTodo",
"RequestMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.batchFetchTodo.req.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
},
"ResponseMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.batchFetchTodo.res.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
}
}
},
"PipelineQueryBatchResolver": {
"Type": "AWS::AppSync::Resolver",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"Kind": "PIPELINE",
"PipelineConfig": {
"Functions": [
{
"Fn::GetAtt": [
"AddEnvVariablesToStash",
"FunctionId"
]
},
{
"Fn::GetAtt": [
"FunctionQueryBatchFetchTodo",
"FunctionId"
]
}
]
},
"TypeName": "Query",
"FieldName": "batchFetchTodo",
"RequestMappingTemplate": "{}",
"ResponseMappingTemplate": "$util.toJson($ctx.result)"
},
"DependsOn": [
"AddEnvVariablesToStash",
"FunctionQueryBatchFetchTodo"
]
}
}
AWS AppSync Data-sources
If you are curious and want to know more, I recommend you to spend a while in the AppSync Console (you can see how resolvers, functions, tables and data types are working together).
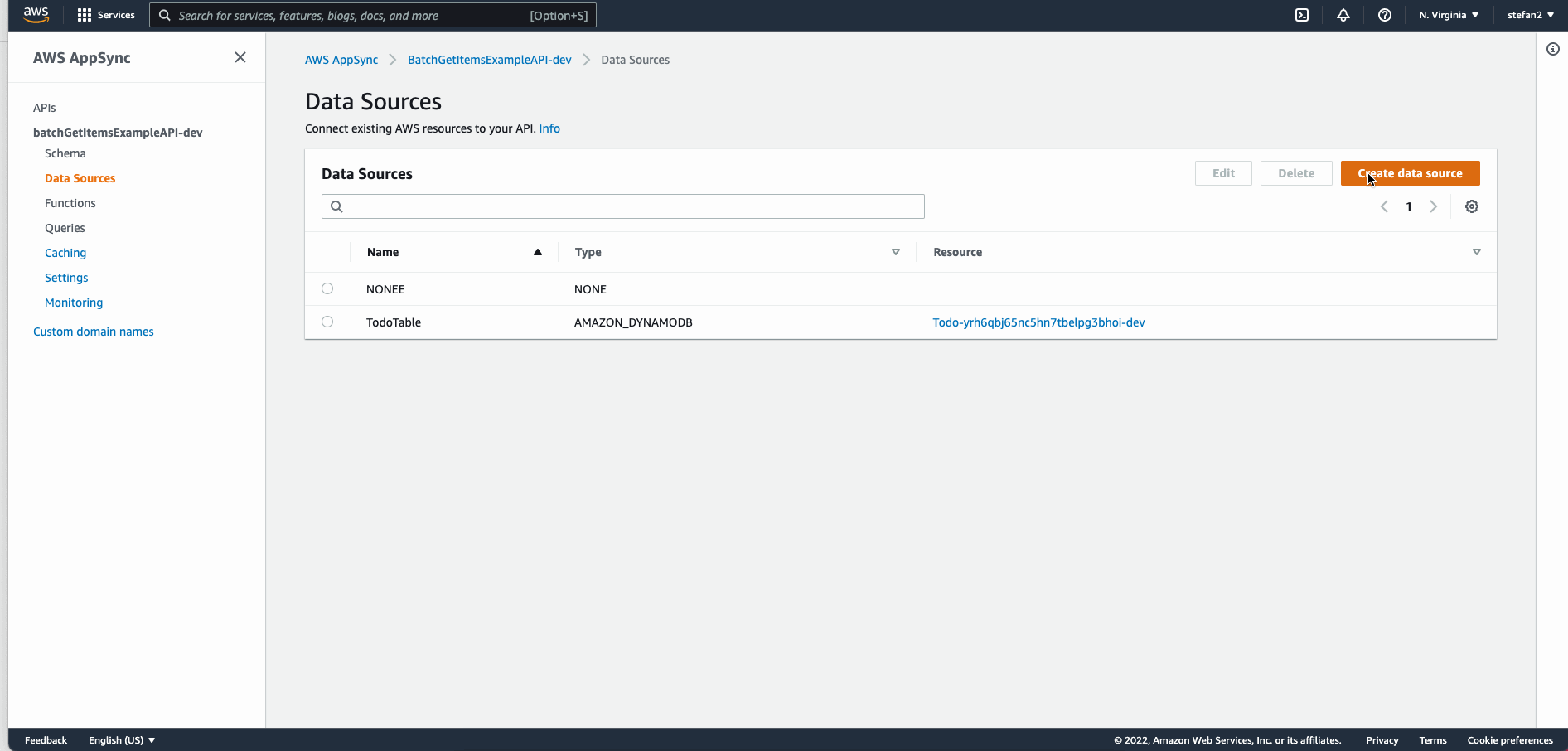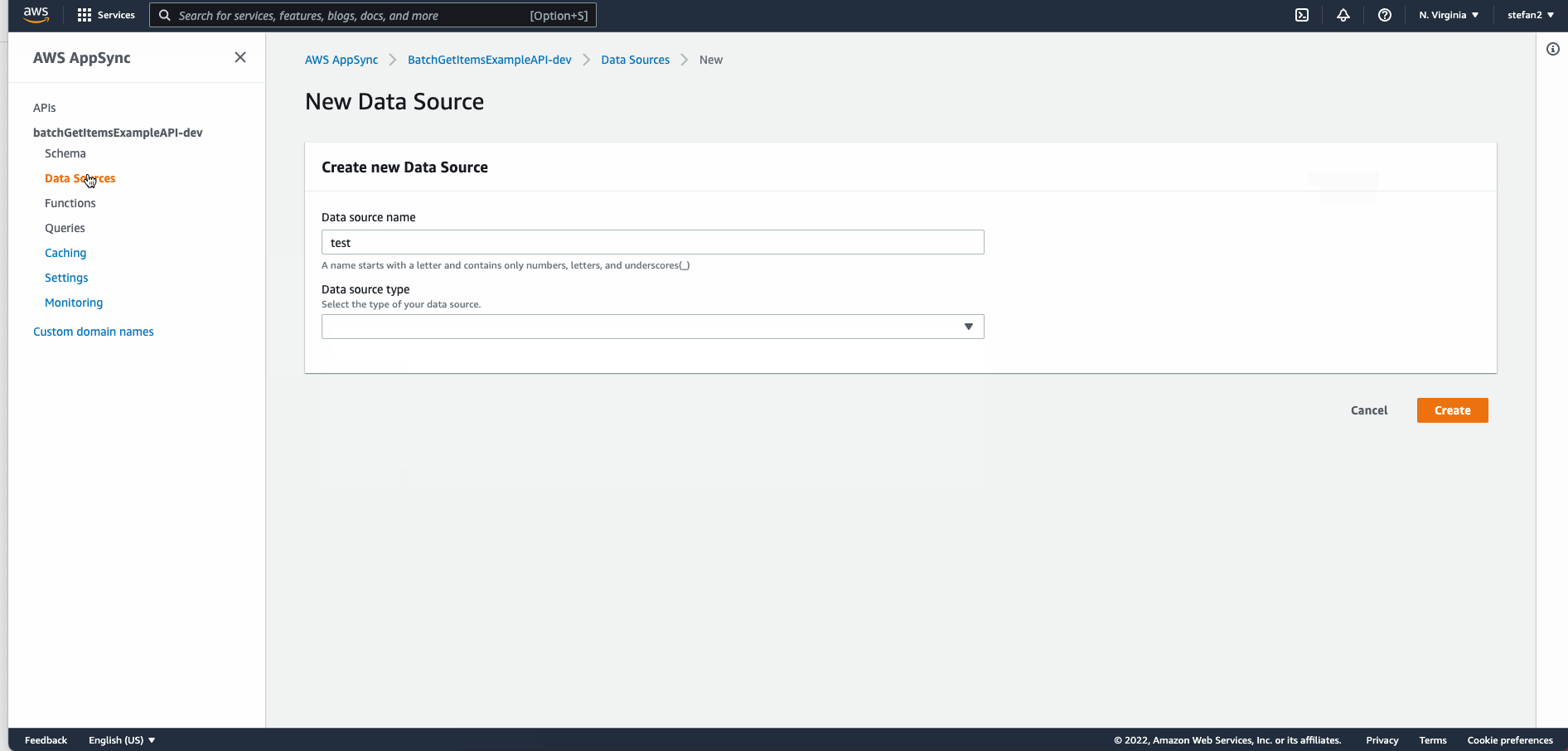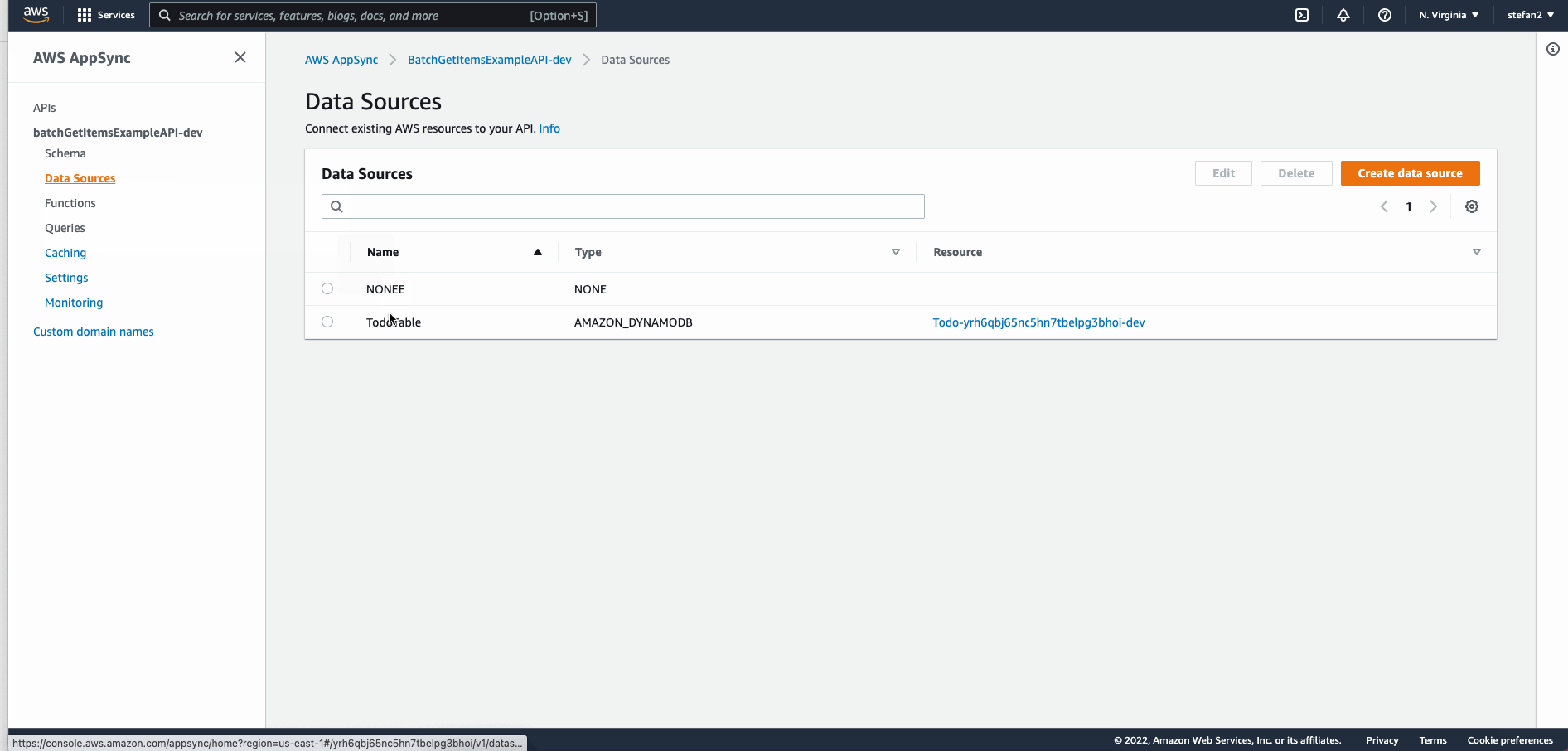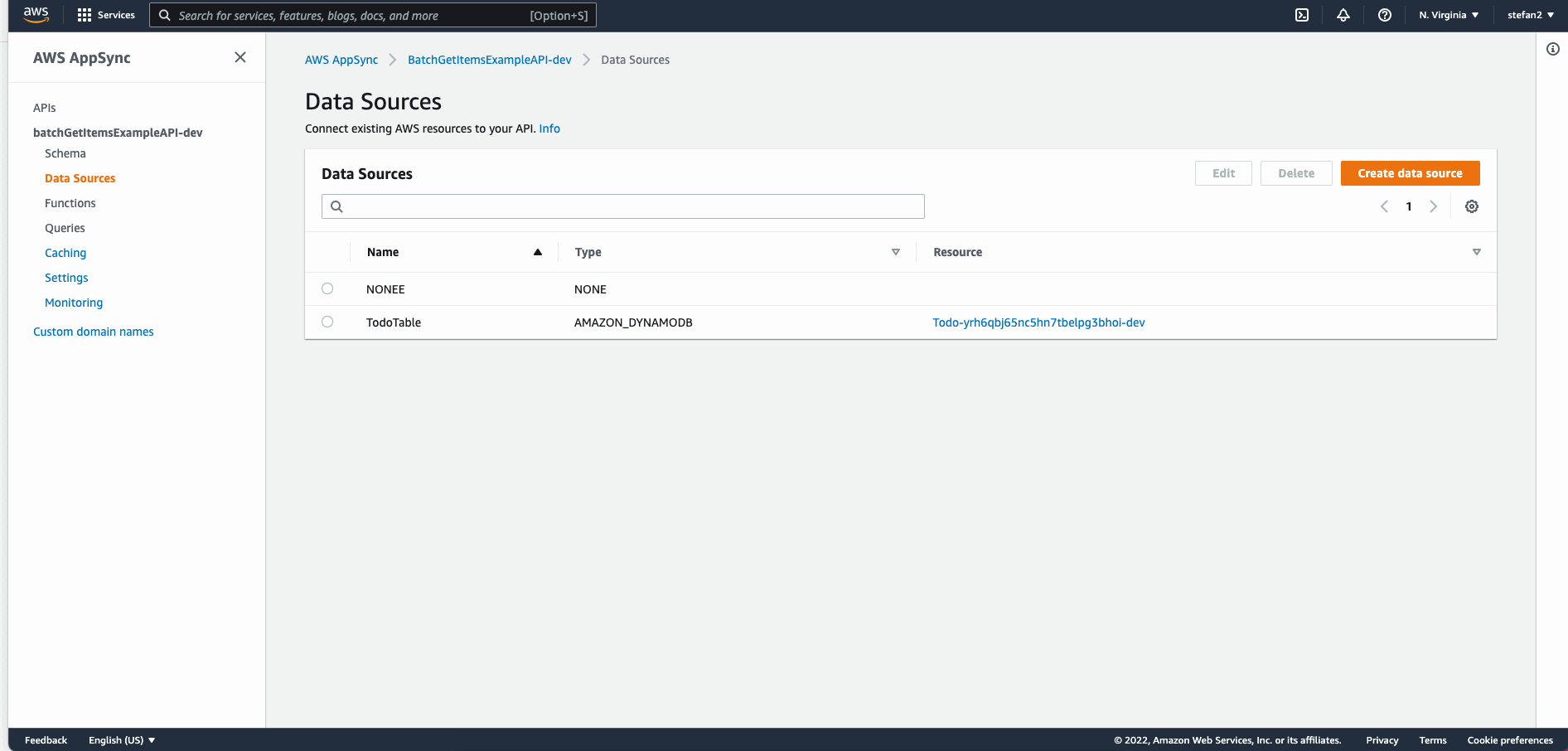
AWS Appsync BatchGetItem With Multiple Tables and AWS Amplify
To demonstrate how to use BatchGetItem to fetch data from different DynamoDB tables, I extended a schema a little bit:
type Todo @model {
id: ID!
name: String!
description: String
priority: String
}
type Note @model {
id: ID!
name: String!
}
# no model annotation here
type TodoNoteResponse {
todos: [Todo]
notes: [Note]
}
type Query {
batchFetchTodo(ids: [ID]): [Todo]
batchFetchTodoWithNotes(todoIds: [ID], notesIds: [ID]): TodoNoteResponse
}I have also added new resolver files:
#if ($ctx.error)
$util.appendError($util.toJson($ctx.error))
#end
#set($todoIds = [])
#foreach($id in ${ctx.args.todoIds})
#set($map = {})
$util.qr($map.put("id", $util.dynamodb.toString($id)))
$util.qr($todoIds.add($map))
#end
#set($notesIds = [])
#foreach($id in ${ctx.args.notesIds})
#set($map = {})
$util.qr($map.put("id", $util.dynamodb.toString($id)))
$util.qr($notesIds.add($map))
#end
{
"version" : "2018-05-29",
"operation" : "BatchGetItem",
"tables" : {
"Todo-${ctx.stash.apiId}-${ctx.stash.env}": {
"keys": $util.toJson($todoIds),
"consistentRead": true
},
"Note-${ctx.stash.apiId}-${ctx.stash.env}": {
"keys": $util.toJson($notesIds),
"consistentRead": true
}
}
}
and
#if ($ctx.error)
$util.appendError($util.toJson($ctx.error))
#end
#set($map = {})
$util.qr($map.put("notes", $ctx.result.data["Note-${ctx.stash.apiId}-${ctx.stash.env}"]))
$util.qr($map.put("todos", $ctx.result.data["Todo-${ctx.stash.apiId}-${ctx.stash.env}"]))
$util.toJson($map)Then, as you would expect I also needed to modify CustomResources.json again:
"Resources": {
"EmptyResource": {
"Type": "Custom::EmptyResource",
"Condition": "AlwaysFalse"
},
"NONEE": {
"Type": "AWS::AppSync::DataSource",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"Name": "NONEE",
"Type": "NONE"
}
},
"AddEnvVariablesToStash": {
"Type": "AWS::AppSync::FunctionConfiguration",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"DataSourceName": "NONEE",
"Description": "Sets $ctx.stash.env to the Amplify environment and $ctx.stash.apiId to the Amplify API ID",
"FunctionVersion": "2018-05-29",
"Name": "AddEnvVariablesToStash",
"RequestMappingTemplate": "{\n \"version\": \"2017-02-28\",\n \"payload\": {}\n }",
"ResponseMappingTemplate": {
"Fn::Join": [
"",
[
"$util.qr($ctx.stash.put(\"env\", \"",
{
"Ref": "env"
},
"\"))\n$util.qr($ctx.stash.put(\"apiId\", \"",
{
"Ref": "AppSyncApiId"
},
"\"))\n$util.toJson($ctx.prev.result)"
]
]
}
},
"DependsOn": [
"NONEE"
]
},
"FunctionQueryBatchFetchTodo": {
"Type": "AWS::AppSync::FunctionConfiguration",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"DataSourceName": "TodoTable",
"FunctionVersion": "2018-05-29",
"Name": "FunctionQueryBatchFetchTodo",
"RequestMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.batchFetchTodo.req.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
},
"ResponseMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.batchFetchTodo.res.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
}
}
},
"PipelineQueryBatchResolver": {
"Type": "AWS::AppSync::Resolver",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"Kind": "PIPELINE",
"PipelineConfig": {
"Functions": [
{
"Fn::GetAtt": [
"AddEnvVariablesToStash",
"FunctionId"
]
},
{
"Fn::GetAtt": [
"FunctionQueryBatchFetchTodo",
"FunctionId"
]
}
]
},
"TypeName": "Query",
"FieldName": "batchFetchTodo",
"RequestMappingTemplate": "{}",
"ResponseMappingTemplate": "$util.toJson($ctx.result)"
},
"DependsOn": [
"AddEnvVariablesToStash",
"FunctionQueryBatchFetchTodo"
]
},
"FunctionQueryBatchFetchTodoWithNotes": {
"Type": "AWS::AppSync::FunctionConfiguration",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"DataSourceName": "NoteTable",
"FunctionVersion": "2018-05-29",
"Name": "FunctionQueryBatchFetchTodoWithNotes",
"RequestMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.batchFetchTodoWithNotes.req.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
},
"ResponseMappingTemplateS3Location": {
"Fn::Sub": [
"s3://${S3DeploymentBucket}/${S3DeploymentRootKey}/resolvers/Query.batchFetchTodoWithNotes.res.vtl",
{
"S3DeploymentBucket": {
"Ref": "S3DeploymentBucket"
},
"S3DeploymentRootKey": {
"Ref": "S3DeploymentRootKey"
}
}
]
}
}
},
"PipelineQueryBatchTodoWithNotesResolver": {
"Type": "AWS::AppSync::Resolver",
"Properties": {
"ApiId": {
"Ref": "AppSyncApiId"
},
"Kind": "PIPELINE",
"PipelineConfig": {
"Functions": [
{
"Fn::GetAtt": [
"AddEnvVariablesToStash",
"FunctionId"
]
},
{
"Fn::GetAtt": [
"FunctionQueryBatchFetchTodoWithNotes",
"FunctionId"
]
}
]
},
"TypeName": "Query",
"FieldName": "batchFetchTodoWithNotes",
"RequestMappingTemplate": "{}",
"ResponseMappingTemplate": "$util.toJson($ctx.result)"
},
"DependsOn": [
"AddEnvVariablesToStash",
"FunctionQueryBatchFetchTodoWithNotes"
]
},
"AppsyncAccessMultipleTablesRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"RoleName": {
"Fn::Sub": [
"AppsyncAccessMultipleTablesRole-${env}",
{
"env": {
"Ref": "env"
}
}
]
},
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "appsync.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
},
"Policies": [
{
"PolicyName": "AppsyncAllowDynamoBatchGet",
"PolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AppsyncAllowDynamoBatchGet",
"Effect": "Allow",
"Action": [
"dynamodb:BatchGetItem",
"dynamodb:BatchWriteItem",
"dynamodb:UpdateItem",
"dynamodb:PutItem",
"dynamodb:DeleteItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query"
],
"Resource": [
{
"Fn::Sub": [
"arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/Note-${AppSyncApiId}-${env}",
{
"env": {
"Ref": "env"
},
"AppSyncApiId": {
"Ref": "AppSyncApiId"
}
}
]
},
{
"Fn::Sub": [
"arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/Todo-${AppSyncApiId}-${env}",
{
"env": {
"Ref": "env"
},
"AppSyncApiId": {
"Ref": "AppSyncApiId"
}
}
]
},
{
"Fn::Sub": [
"arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/Note-${AppSyncApiId}-${env}/*",
{
"env": {
"Ref": "env"
},
"AppSyncApiId": {
"Ref": "AppSyncApiId"
}
}
]
},
{
"Fn::Sub": [
"arn:aws:dynamodb:${AWS::Region}:${AWS::AccountId}:table/Todo-${AppSyncApiId}-${env}/*",
{
"env": {
"Ref": "env"
},
"AppSyncApiId": {
"Ref": "AppSyncApiId"
}
}
]
}
]
}
]
}
}
]
}
}
},As you could see above, I wanted to add AppsyncAccessMultipleTablesRole (IAM role) because when trying to use BatchGetItem with multiple tables, I always got one of following errors:
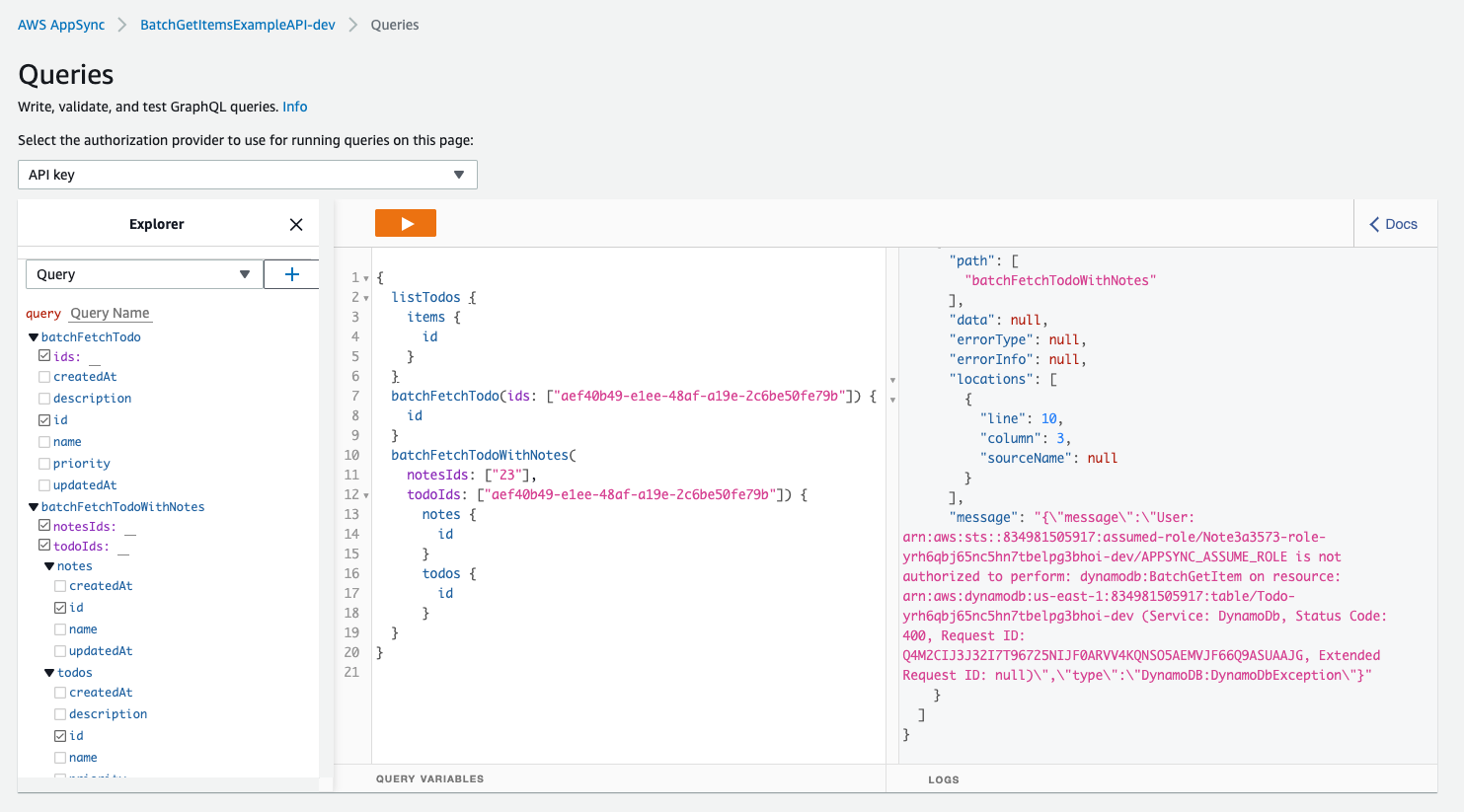
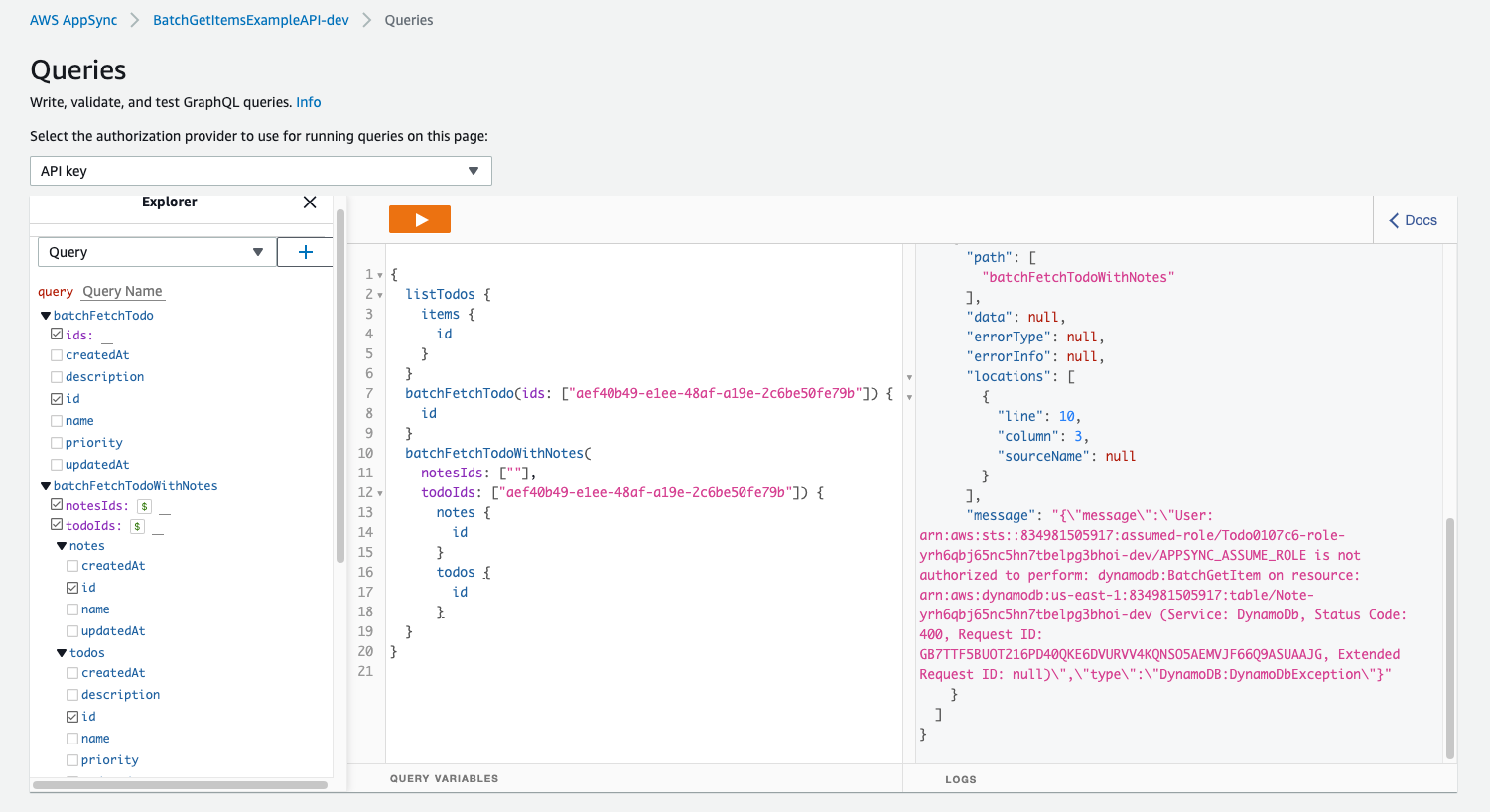
This is because the fact, that we can only specify just one "DataSourceName" for AWS::AppSync::FunctionConfiguration (take a look at CustomResources.json few lines above to understand).
Even AppSync UI Console is able to display only one table as datasource although you can use BatchGetItem to retrieve items from different tables according to this docs.
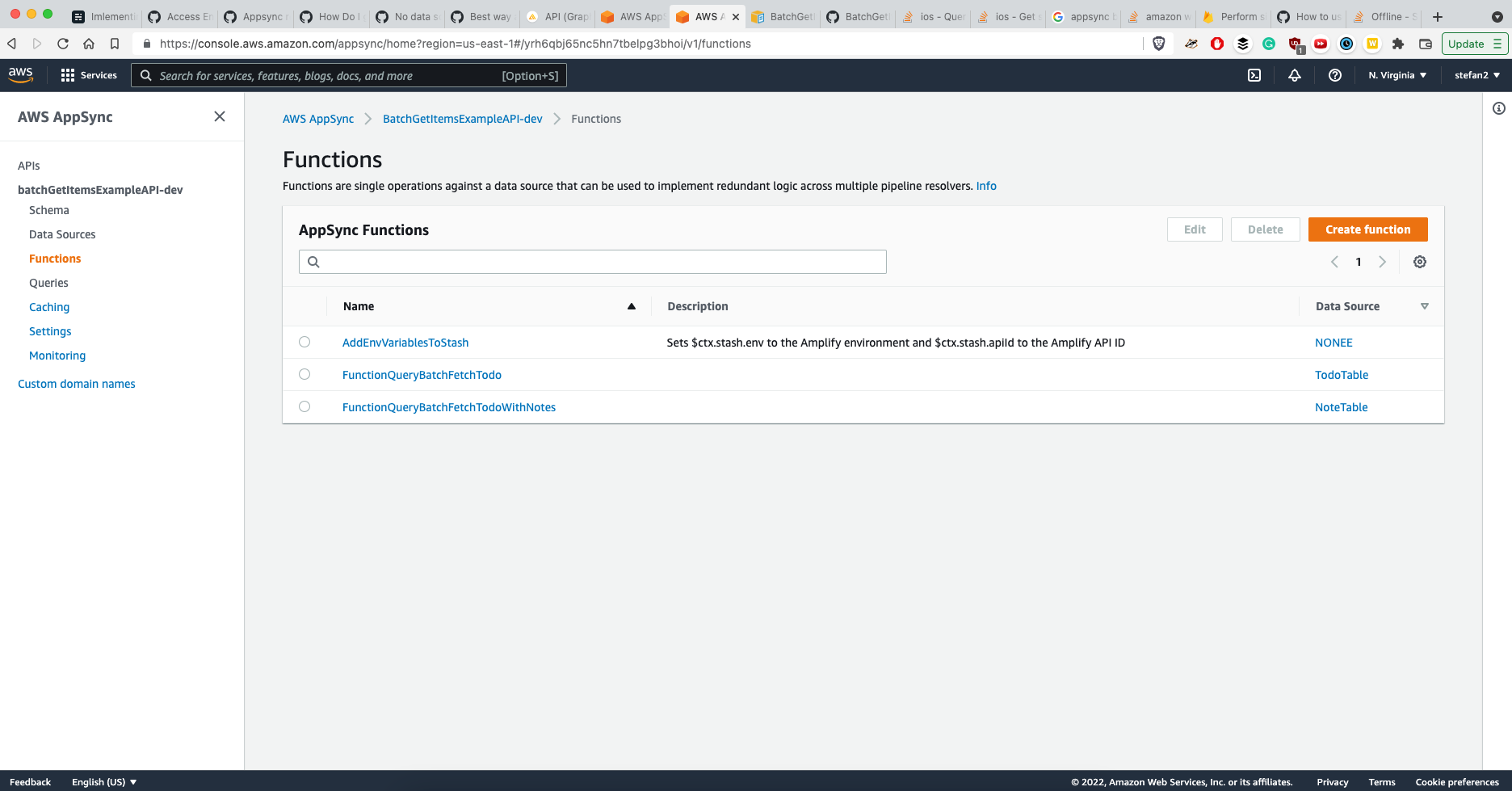
Here is the official AppSync explanation:
Roles are tied to data sources in AWS AppSync, and resolvers on fields are invoked against a data source. Data sources configured to fetch against DynamoDB only have one table specified, to keep configuration simple. Therefore, when performing a batch operation against multiple tables in a single resolver, which is a more advanced task, you must grant the role on that data source access to any tables the resolver will interact with. This would be done in the Resource field in the IAM policy above. Configuration of the tables to make batch calls against is done in the resolver template, which we describe below.
I made an attempt to attach the IAM role (defined in CustomResources.json) to the Appsync Datasource but it did not worked as expected - if you figure it out, please let me know on Twitter (I am @stefanmajiros) so I could update this blog post. For now, I have just recorded this short GIF about how you can attach IAM roles to AppSync manually using AWS Console (I know it's not optimal solution, but still better than nothing):
P.S.: I have suspicion, that we could solve it by defining DataSources for tables explicitly in the CustomResources.json and then just specify Service Role property for them that would point at our custom role that allows reading from multiple tables - however, I did not have time to explore this path yet.
Result / Final Solution
Except attaching IAM role, we can say it's done:
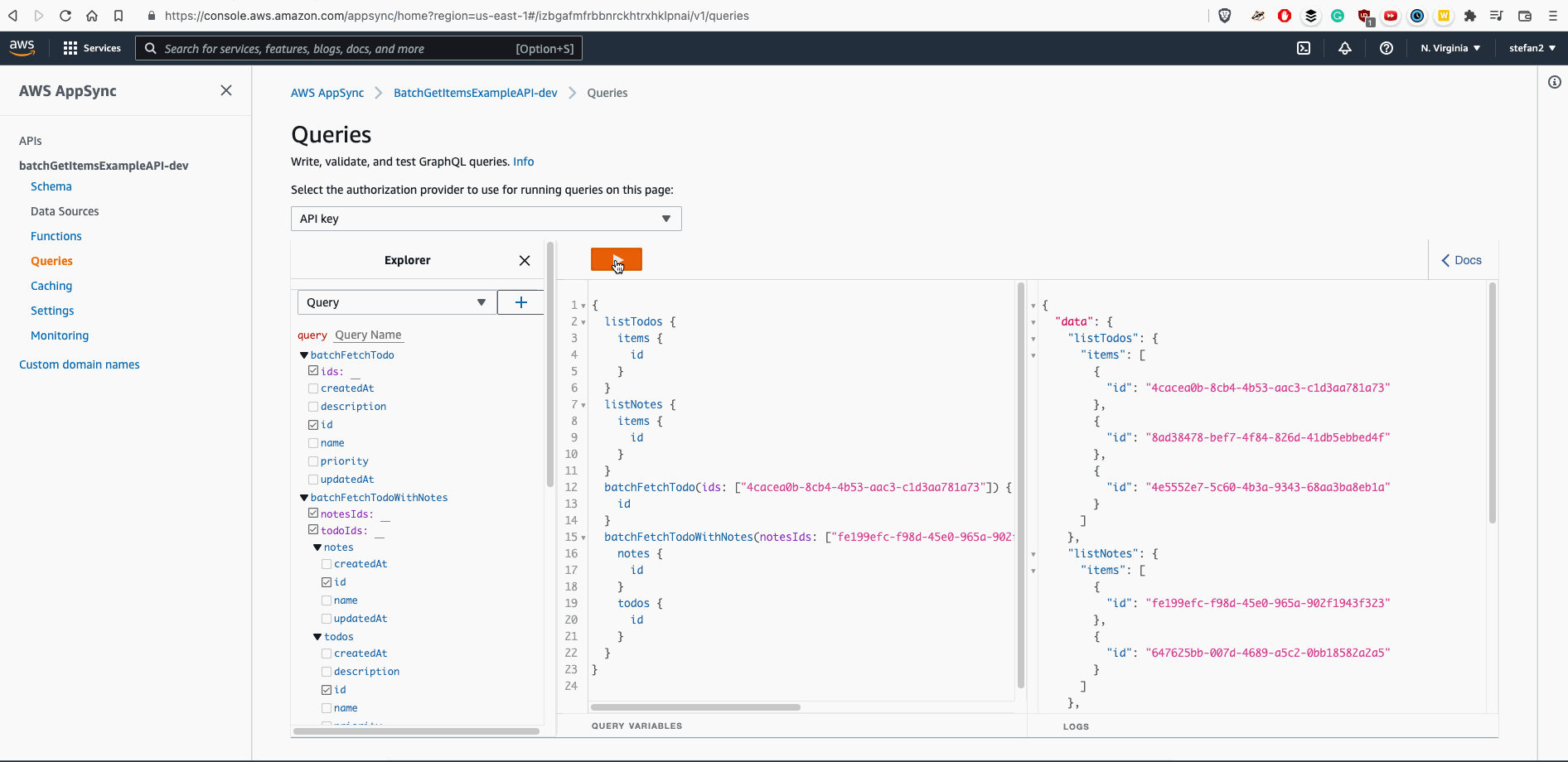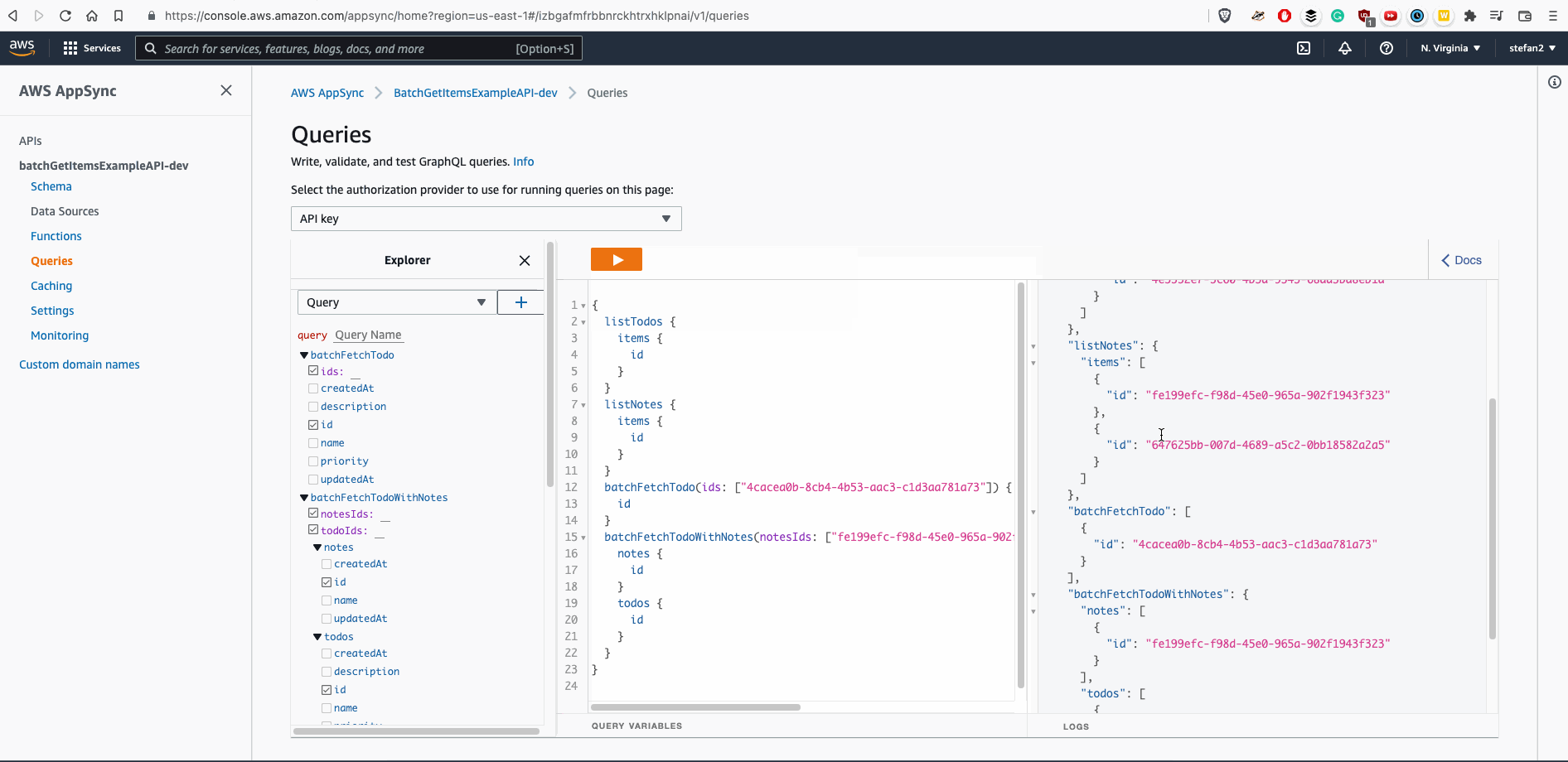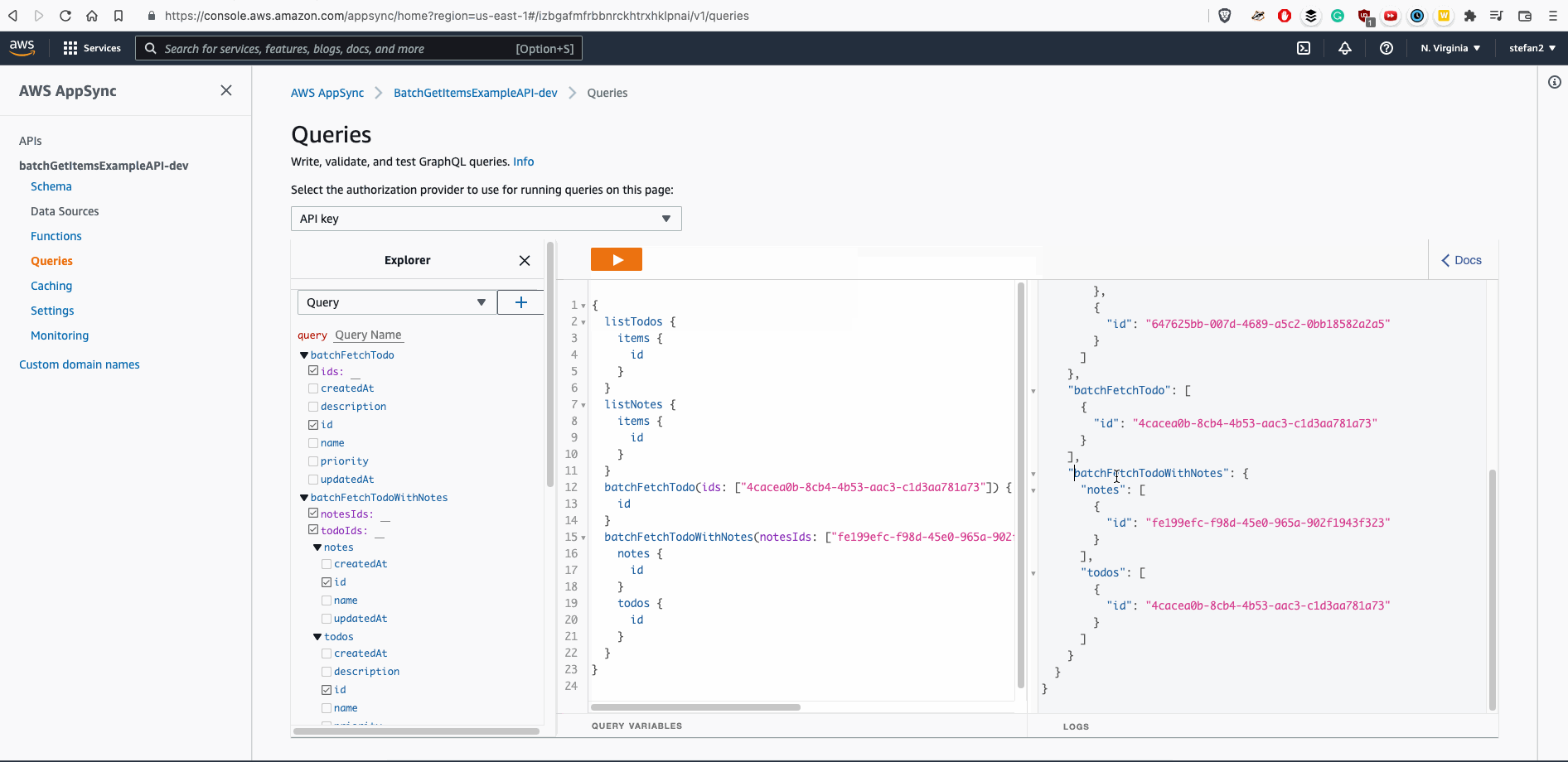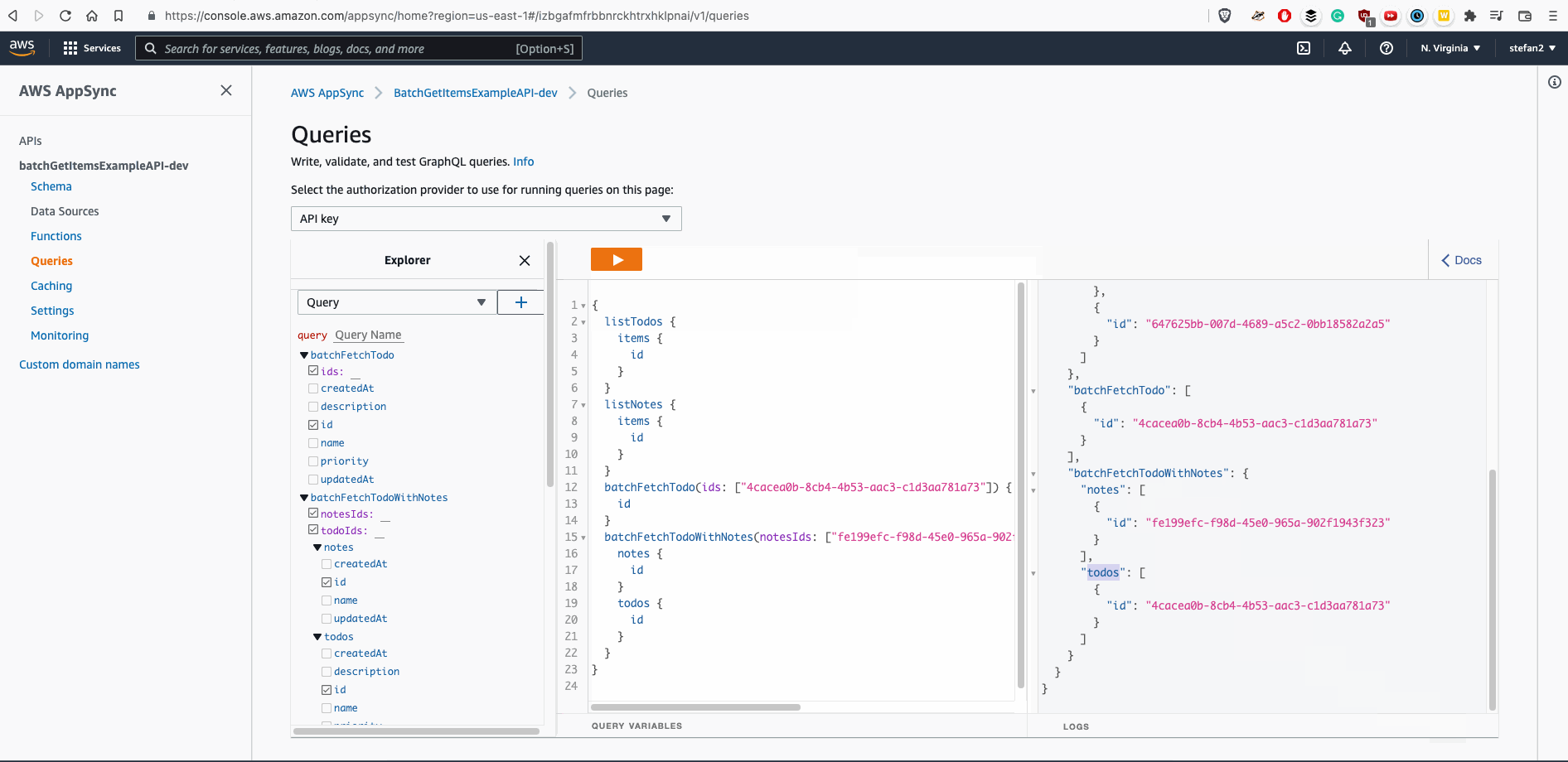
Recommendation: If you want to speedup process of writing Velocity Templates, feel free to use AWS AppSync Console - it would generate basic skeleton of Velocity Template for you.
Check this sample:
Now, I hope you understood the process of adding Custom GraphQL Resolvers into Appsync / AWS Amplify!
Source code is here.